On GPU Usage
So I started making a game engine with C++ and DirectX11. It's been a pretty cool journey thus far, and it's improved my knowledge of games and 3D graphics 10-fold. I totally recommend the process to anybody looking to learn a little more about how modern game engines work.
At the core, there's an infinite loop consisting of input, simulation, and draw, but as I've come to learn, a vast majority of development time is spent on that third part. Using a powerful language like C or C++, one can write a program that sends commands to the GPU, which in turn draws triangles for us. That's pretty much how games work in a nutshell.
Unfortunately, or fortunately, sometimes things can get a little challenging. The challenge that I've been tackling over the last week or so has to do with GPU usage. When I first opened up Task Manager to check in on things, I was a bit surprised to see some very inconsistent usage. And here's what's worse, this is idle behavior. Meaning I didn't have to touch the app, for gpu usage to spike or drop 10%.
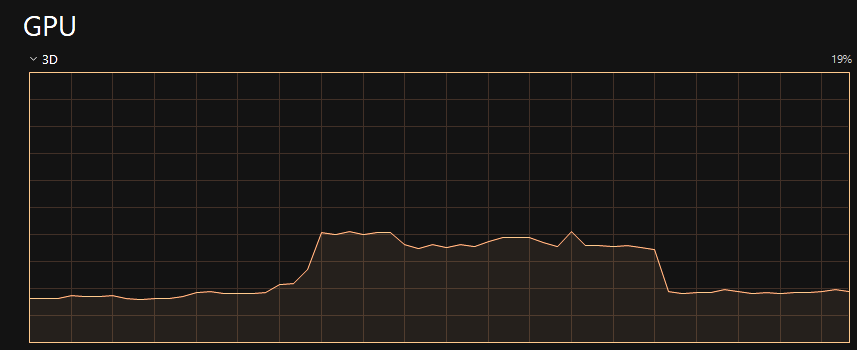
My first point of investigation was to add timestamps using this article as a jumping off point. What I was seeing in the resulting timestamps was reflective of the usage pattern above. First Pass time would average 1.5ms, then all of a sudden it would kick into high gear and spike to 3ms, sometimes going as high as 6ms. The thing is, it would seem to "lock in" to to these very disparate usage levels, and I did not like that one bit. Remember we are talking about IDLING behavior here. Stuff should not be changing this much frame to frame.
Anyway a bit of googling seemed to lead me nowhere. Apparently the only folks who look at gpu usage are gamers. So due to the lack of search-ability and vocabulary around the issue, I was forced to look at how I was doing things from the ground up in order to improve idle gpu usage.
Problem #1: buffer usage flags
So with DirectX you have a few options for buffer usage.
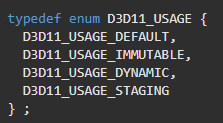
As per some tutorials I followed, I made my buffers default usage. This was great, and it got me off the ground, but I think this is what lies at the core of the issue. According to the Docs, I should be using dynamic for most of my buffers, because they were being updated more than once a frame.
So things like model, light, and camera matrices that get changed often, should really be DYNAMIC, I think... Also supposedly using the Map() and Unmap() methods is more efficent than UpdateSubresource. And while the latter worked, I believe it contributed to some bottlenecking.
Problem #2: Each object having it's own vertex and index buffer
I found that it was quite easy when getting started to create a vertex buffer when loading the mesh, and passing it to the gpu when drawing. But since we typically have 5 passes for geometry (4 shadow cascades and 1 draw), this meant that we would be changing the vertex and index buffers a lot during the opaque draw passes.
The fix here is simple in theory, just use a single vertex buffer and index buffer for all geometry of similar form. By similar form I mean containing 8 floats - 3 for position, 3 for normal, and 2 for texture coordinates. With a consistent stride, it is easy enough to cram in a whole bunch of objects into a single vertex buffer, and reference each one via DrawIndexed()
For example, my program only uses 2 vertex arrays. One for 3D geometry, and one for 2D, so the call to switch vertex buffers happens only twice per frame. If (and when) I want to incorperate vertices of other forms, like particles, or perhaps dynamic surfaces, I may need to create additional vertex buffers to account for the dynamic nature, or different strides.
Problem #3: Poor buffer management
Most of this is speculation, but I'm pretty sure the way I was managing buffers was bad. For example the way I was managing the model matrix buffer(s). See I only allocated one model matrix buffer for the whole program, a whopping 64 bytes. Every single time a new model would be drawn that buffer had to be overwritten. And worse, going back to Problem 1, I was using UpdateSubresource on a default buffer which is not going to be as fast as we like.
So in the case of the model buffer, I decided to allocate one buffer per transform. So if we had 1000 objects on screen at a time, we would only be using about 64 KB of graphics memory for the model matrices. That seems like a small amount these days, so I'll roll with it. The big savings here is writing to gpu memory less often.
I repeated this with my color buffers, which are comparable to model buffers. There should be one per model, containing color, shadow bias, and maybe a couple more things.
Again the goal here is simply to reduce how frequently a single ID3D11 buffer is written to, especially if it is not flagged for dynamic usage.
Key take-aways:
1. Use Dynamic buffers for dynamic data
2. Group vertices into larger vertex / index arrays.
3. Allocate per-object buffers to reduce gpu memory write / overwrite times
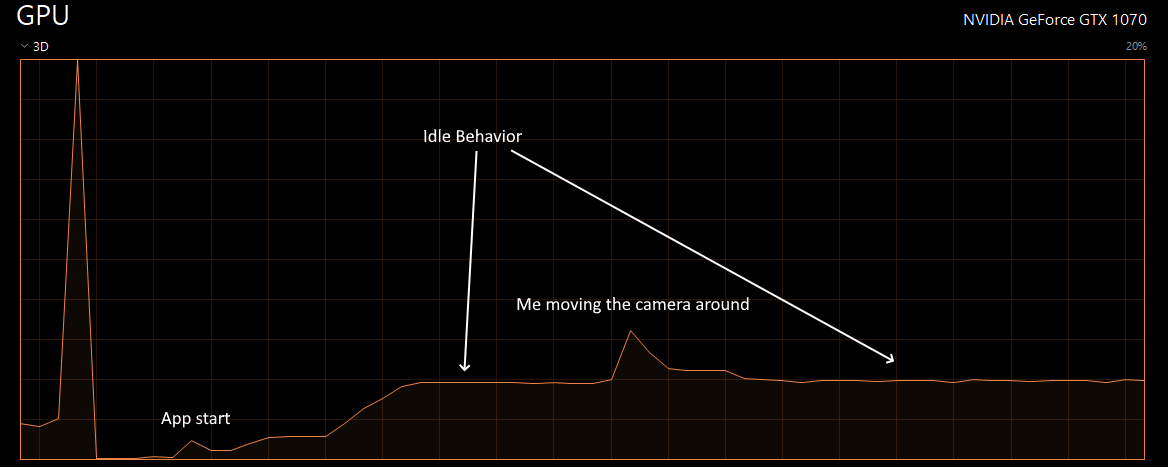
In the end, I was able to produce an executable that rendered with more consistent gpu usage, and a lower average usage. I think some of these concepts may be obvious to experienced GPU programmers, but for me, it still feels like baby steps. After ripping apart the plumbing and rethinking things, I'm very happy with the results. It's still not a perfectly flat line as I would hope seeing that the camera, light, and models are not moving during this screen grab, but it's a heck-of-a-lot flatter than it was before. One step back, but two steps forward.
Leave a comment
Log in with itch.io to leave a comment.